자연어 처리(NLP)를 본격적으로 공부하기 전에 기존에 사용하던 자연어 처리 기법인 Bag-of-Words Representation과 이를 활용한 Naive Bayes Classifier에 대해 알아보고자 한다.
Bag-of-Words
Bag-of-Words는 입력된 문장의 단어를 수치화하는 방법중에 하나로 문장 안 단어의 순서를 고려하지 않는 출현 빈도수 기반의 간단한 단어 표현 방법 중 하나이다. BoW가 생성되는 과정을 설명하자면 문서 내 단어별로 고유의 정수 인덱스를 할당하여 단어 집합(사전)을 생성한 뒤 one-hot vectors의 합으로 문장을 표현하는 것이다. Bag-of-Words는 국소표현 (Local Representation)으로 해당 단어 그 자체만 보고 특정값을 매핑하여 표현하는 방법의 일종이다.
EX)
“John really really loves this movie”
“Jane really likes this song”
- Vocabulary = {“John”, “really”, “loves”, “this”, “movie”, “jane”, “likes”, “song”}
Jone = [1 0 0 0 0 0 0 0]
really = [0 1 0 0 0 0 0 0]
…
song = [0 0 0 0 0 0 0 1]
Bag-of-Words
- Jone really really loves this movie => [1 2 1 1 1 0 0 0]
- Jane really likes this song => [0 1 0 1 0 1 1 1]
위처럼 Bag-of-Words Representation는 어떤 단어들이 몇번 나왔는지 파악할 수 있지만 단어들이 어떠한 순서를 가지고 구성되었는지는 파악할 수 없다는 단점이 있다. 또한 한번도 출현하지 않은 단어들은 처리를 하지 못하고 단어의 양이 많아지면 벡터의 차원이 커져 연산량이 많아지게 된다는 단점도 있다.
Naive Bayes Classifier
Naive Bayes Classifier는 Bag-of-Words를 활용한 대표적인 문서 분류 기법으로 베이즈 정리를 이용하여 조건부 확률 을 계산해 결과를 도출해내는 기법이다. 이를 통해 이전 데이터를 기반으로 각 클래스의 확률을 추정하여 새로운 데이터를 분류한다.
베이즈 정리는 이미 발생한 다른 사건의 확률을 고려하여 사건이 발생할 확률을 찾는 것으로 위와같이 수학적으로 표현된다.

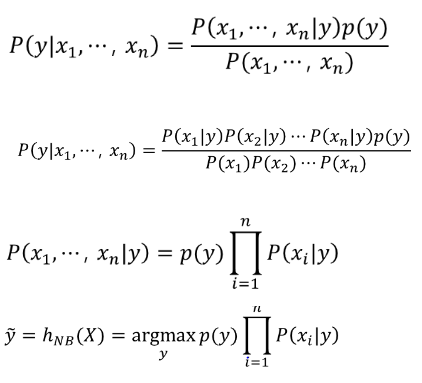
P(X)가 X가 일어날 확률, P(Y)가 Y가 일어날 확률, P(Y|X)가 X가 일어나고나서 Y가 일어날 확률, P(Y|X)가 Y가 일어나고나서 X가 일어날 확률이라고 해보자. 이때 P(Y|X)를 쉽게 구할 수 있는 상황이라면, 위와같은 식을 통해 P(X|Y)를 구할 수 있다. 여기서 모든 기능은 독립적이므로 문서 내 문장의 단어들이 x1, x2 … xn 이라고 한다면 주어진 문장에 각 단어들이 포함되어있는 확률을 계산하여 클래스를 분류한다.
예시를 살펴보자. 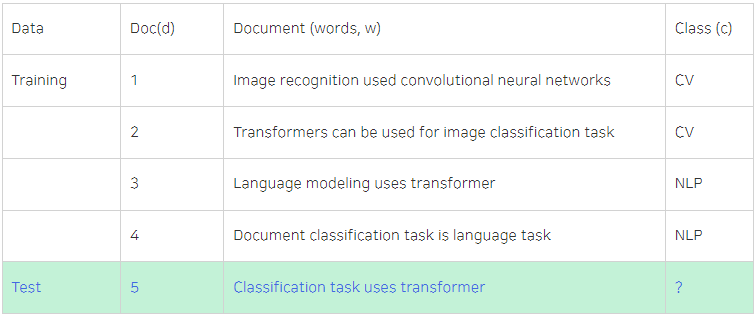
위 표는 Training 문장을 통해 Test 문장이 CV, NLP 클래스중 어떤 클래스에 속하는지 분류하고자 하는 것이다. 따라서 P(Ccv) = 1/2, P(CNLP) = 1/2 이고 5번째 문장이 CV클래스에 속할 확률인 P(Ccv|d5)는 1/2 * 1/14 * 1/14 * 1/14 * 1/14 이며 5번째 문장이 NLP클래스에 속할 확률인 P(CNLP|d5)는 1/2 * 1/10 * 2/10 * 1/10 * 1/10이다. 이와 같이 주어진 문장의 각 단어가 클래스별 문장에 몇 번 등장했는지를 계산하여 더 큰 값을 가지는 클래스로 분류가 되는 방식인 것이다.
Navie Bayes Classifier는 이러한 베이즈 정리를 이용하여 새로운 데이터를 분류한다. 하지만 위 분류기는 특정 단어들이 분류하고자 하는 클래스 문장에 많이 등장하여 확률이 높아졌다고 해도 Training 문장에서 1번도 등장하지 않았다면 확률이 0이 되어버리는 문제가 존재한다.