Seq2seq와 같은 모델에서 출력값을 생성하는 알고리즘에는 여러가지 방법이 있다. 대표적으로 Greedy Decoding, Exhaustive Search, Beam Search가 있다.
- Greedy Decoding: 출력값을 생성하는 현재 시점에서 가장 확률이 높은 값을 선택하는 것
- Exhaustive Search: 매 time step마다 가능한 모든 경우의 수를 고려해 값을 선택하는 것
- Beam Search: Greddy Decoding과 Exaustive Search의 단점을 보완하는 방법으로 매 time step마다 k개의 경우의 수를 고려하여 확률이 높은 값을 선택하는 것
Beam Search
Beam Search는 위에서 설명한 것과 같이 매 time step에서 k개의 경우의 수만 고려하여 현 시점의 단어를 선택하는 기법으로 이때 k를 Beam Size라고 한다.Beam Size는 대체로 5~10의 값을 가지며 hypotheses y1, y2, ···, yt는 log 확률로 계산한다. 단조증가함수이므로 최대 확률을 갖는 값이 똑같지만 product계산이 아닌 sum계산을 하므로 연산이 더 수월하다.

Exhaustive search처럼 모든 경우의 수를 다 고려하는 것이 아니기 때문에 가장 좋은 결과를 보장하진 않지만 계산적인 측면에서 훨씬 더 효율적이다.
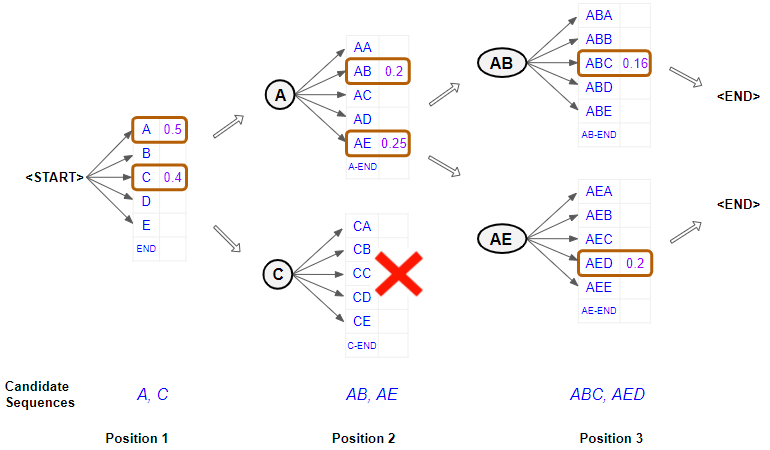
위 이미지를 예로 들면 Beam Size가 2일 때 각 time step에서 후보값들 중에 확률이 가장 높은 값 2개를 선택하여 다음 time step으로 넘어가게 되는 방식이다. 모든 후보에서 <END>토큰이 나오게 되면 탐색을 종료하고 선택된 후보들 중에서 확률이 가장 높은 결과들을 선택하게 된다.
이러한 Beam Search에서 Beam Size인 k의 값을 1로 설정하게 되면 위에서 설명한 Greedy Decoding이 되는것이고 k를 무한대의 값으로 설정하게 되면 Exhaustive Search가 되는 것이다.
NLP모델 평가 지표
자연어 처리 모델이 얼마나 잘 학습되었는지 파악할 수 있는 평가 지표에 대해 알아보자. 먼저 기본적인 평가지표는 Precision(정밀도)와 Recall(재현율), F-measure이다.
- Precision(정밀도): 예측 결과가 노출 되었을 때 실질적으로 느끼는 정확도를 나타내는 값 = 맞은 단어의 수 / 예측한 문장의 길이
- Recall(재현율): 정답에 해당하는 정보들이 예측값에 얼마나 포함되어 있는지에 따른 값 = 맞은 단어의 수 / 정답 문장의 길이
- F-measure: 정확도와 재현율 중 더 작은 값에 높은 가중치를 부여하여 평균을 내는 값 = Precision과 Recall의 조화평균 = 2(precision * recall)/(precision + recall)
예를들어
정답: Half of my heart is in Havana ooh na na
예측한 문장: Half as my heart is in Obama ohh na
일때 정밀도의 값은 7/9 = 78%, 재현율은 7/10 = 70%, F-measure의 값은 (0.78*0.7)/{0.5*(0.78+0.7)} = 73.78%이다.
생성 모델에서는 일반적인 평가지표인 정확도를 사용하지 않는다. 그 이유로는 실제 정답이 You very cute라는 문장을 모델이 Oh You very cute라는 문장으로 예측을 했다고 하면 우리가 보기에는 거의 다 맞았다고 생각되어지지만 각 time step에서 매치되는 정답과 예측값이 다르기 때문에 정확도는 0이되어 버린다. 이와 같은 이유 때문에 정확도를 사용하지 않는다.
3가지 평균 방식
- 산술평균 : n개의 값을 더한 후, n으로 나눠준 값
- 기하평균 : n개의 값을 모두 곱한 값의 n제곱근
- 조화평균 : 주어진 값들을 역수를 취하여 산출평균을 구한 후 역수를 취한 값
모든 경우에서는 산술평균 >= 기하평균 >= 조화평균 의 값을 가진다.
BLEU Score
BLEU Score는 기계번역에서 많이 쓰이는 평가지표로 기계 번역 결과와 정답이 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 방법이다.

수식을 보면 min값을 곱해주는 걸 알 수 있는데 이는 brevity penalty라고 하며, reference 문장보다 예측 문장이 짧을 때, 1이하의 값을 곱해서 precision의 값을 낮게 보정해주는 역할을 한다.
BLEU Score의 특징으로는 먼저 recall(재현율)이 아닌 precision(정밀도)를 기반으로 성능을 측정한다는 점이다. 그 이유는 번역을 할 때 예측한 문장에서 정답 문장의 단어가 몇개정도는 빠져도 문장의 의미가 크게 변하지 않지만 문장에 없는 단어를 예측하게 되면 영향이 클 수 있기 때문이다. 즉, 재현율이 낮아져도 큰 문제가 없지만 정밀도가 낮아지면 문제가 생길 수 있다는 것이다. 또 다른 특징으로는 n-gram의 n값에 따라 문장을 나누어 정답과 얼마나 일치하는지 다각도로 평가한다는 점이다. 여기서 n-gram이란 문장에서 n개의 단어가 연속으로 이어질 경우를 나타낸다. 예를 들면

이 이미지에서 1-gram일때는 half, my, heart, is, in, ooh, na 7개가 일치하지만 3-gram에서는 my heart is, heart is in 2개만 일치하게 된다. 이러한 n-gram평가방식에서는 단어들이 일치하는 비율이 높더라도 정답 문장과 연속으로 일치하지 않드면 BLEU Score가 0으로 나올수 있는 단점이 있다.