Character-Level Language Model
요즘 자연어 처리에서의 최신 트렌드는 GPT와 같은 거대언어모델(LLM)이라고 할 수 있다. 하지만 LLM을 알기 위해서는 먼저 언어모델을 알아야 한다. 언어 모델(Language Model)은 이전에 등장한 문자열을 기반으로 다음에 등장할 단어를 예측하는 테스크이다. 그 중에서도 간단한 Character-level Language Model은 문자 단위로 문자를 입력 받고 다음에 올 문자를 예측하는 모델이다. 예를 들어 hello라는 단어에서 h가 입력되면 e를 예측해 출력하고 e가 다시 입력되어 l을 예측해 출력하는 것이다.
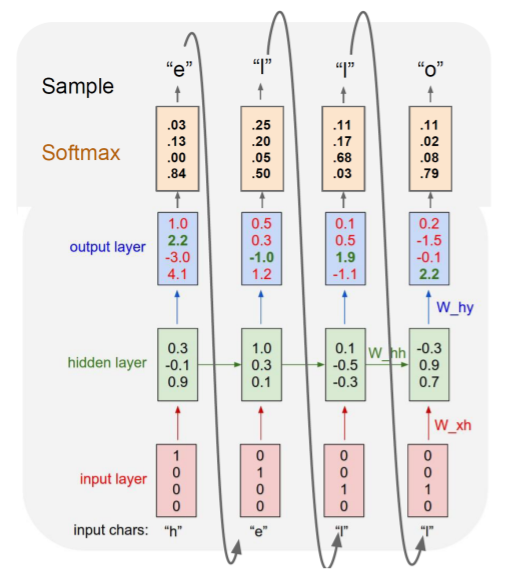
여기서 각 타임스텝별로 output layer를 통해 차원이 4(유니크한 문자의 개수) 벡터를 출력해주는데 이를 logit이라고 부르며, softmax layer를 통과시키면 One-hot vector 형태의 출력값이 나오게 된다.
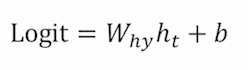
그래서 출력된 One-hot vector를 통해 만들어놓은 Vocabulary에 맞는 문자를 출력하는 것이다. 그래서 모델이 훈련 과정을 거치면서 파라미터값이 조정되고 맞는 문자를 출력하도록 훈련되는 모델인 것이다.
EX)

Backpropagation Through Time(BPTT)
Character-level Language Model과 같은 RNN은 BPTT와 Truncation을 통해 학습을 하게 된다.
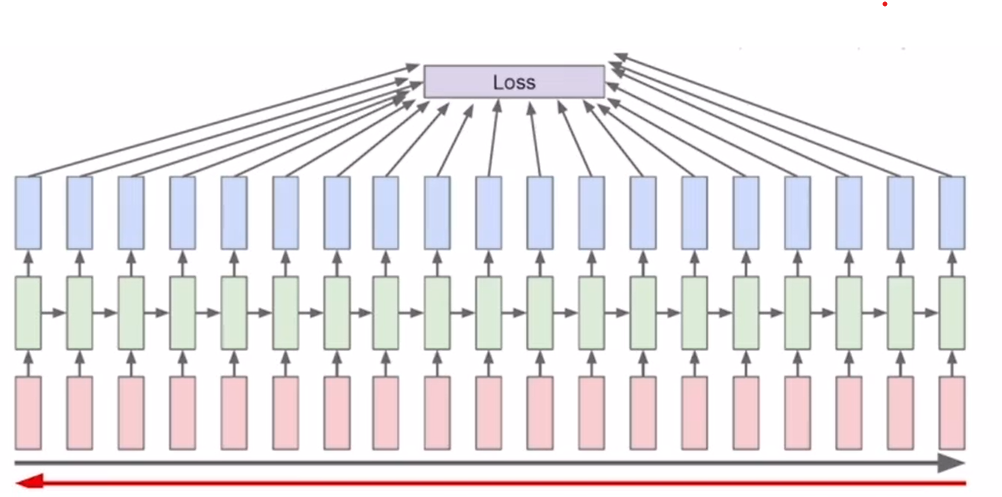
RNN모델은 매 타임 스텝마다 입력이 주어지고 각 입력에 의해 만들어진 hidden-state vector를 통해 output layer에 각자 통과 시켜준 후 예측값을 도출한다. 그 예측값과 실제 다음에 나와야 하는 Ground Truth를 비교하여 Loss Function을 구한다. 그 후 역전파를 진행하면서 Loss function을 이용해 파라미터 W를 미분한 값인 gradient를 통해 학습을 한다. 그래서 BPTT는 위와 같이 RNN에서 타임 스텝마다 계산된 weight를 역전파를 통해 학습하는 방식이다.
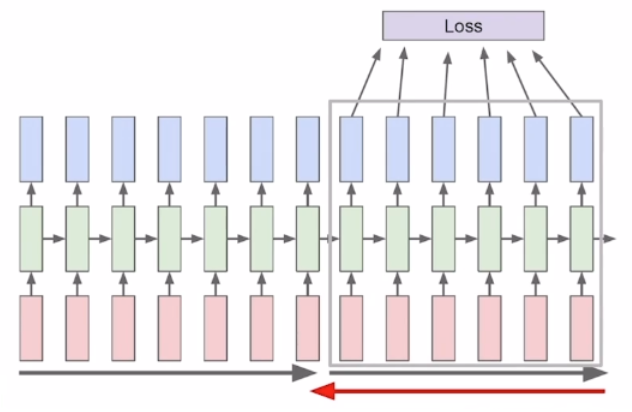
RNN은 학습을 할 때 위 그림처럼 입력을 순차적으로 받으며 출력을 하는데 이때 사용할 수 있는 리소스는 제한이 있어 입력의 길이가 너무 길어지면 다 학습할 수 없기 때문에 일정한 간격으로 잘라서 학습에 사용하는 것을 Truncation이라고 한다.
RNN의 단점
앞서 다루었던 Vanilla RNN의 학습 방식에는 치명적인 단점이 존재한다. 위에서 설명했듯이 RNN은 가중치 W를 미분한 값인 기울기값 gradient를 이용해 가중치를 업데이트 시킨다. 그런데 이 학습 과정에서 가중치를 업데이트 할 때 사용되는 기울기가 기하급수적으로 증가하거나 점차 줄어들어 0에 가까워지는 문제가 발생할 수 있다. 그 문제가 바로 Vanishing/Exploding Gradient Problem이다. Ex)
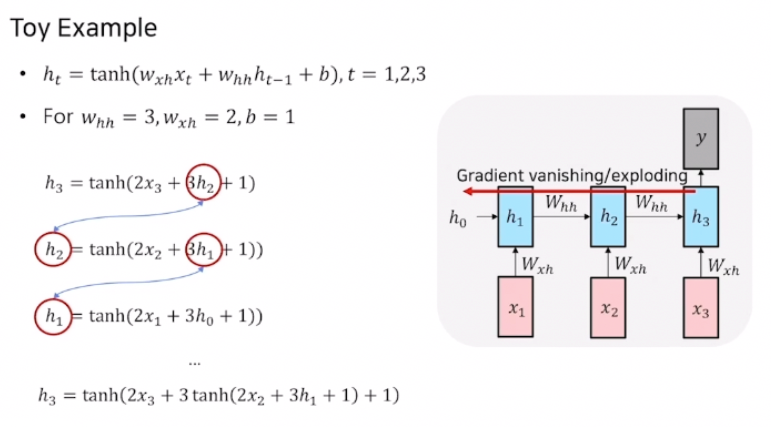
위 예시에서는 time step이 3이고 가중치 W를 스칼라 값이라고 가정하였다. ht를 구하기위한 함수가 위와 같을 때 h3를 구하는 식은 h1으로 표현할 수 있는것을 볼 수 있다. BPTT를 진행하기 위해서 역전파 과정을 수행해 이전 time stop의 기울기를 구하게 되면 Whh값이 3이므로 3이 속미분되어 나오게 된다. time step이 3이므로 결국 기울기는 3 * 3이 된다. 기울기가 3 * 3이라고하면 기울기가 Exploding되는것은 아닌것같아 보이지만 만약 time step이 더 늘어나 10, 20, 100 … 이 된다면 기울기가 3¹⁰, 3²⁰, 3¹⁰⁰ … 이 되어 기하급수적으로 늘어나게 되는 것이다. 비슷하게 W의 값이 1보다 작다면 미분값은 기하급수적으로 작아지게 되어 0에 수렴하게 된다. 이와 같이 계산하게 된다면 Vanishing/Exploding Gradient Problem이 발생하고 time step의 길이가 길어질수록 학습이 잘 이루어지지 않는 Long-Term-Dependency를 일으키게 된다.