Sequence-to-Sequence 모델은 앞서 나왔던 RNN의 구조 중 Many-to-many의 형태에 속한다. 입력이 Sequence, 출력도 Sequence인 형태에서 입력 Sequence를 모두 읽은 후 출력 Sequence를 예측하는 모델이다.
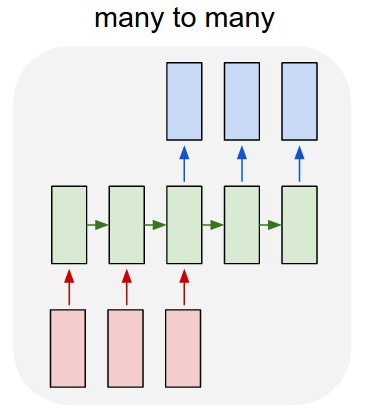
Seq2seq의 구조
Sequence-to-Sequence의 구조는 입력된 문장을 읽어들이는 Encoder와 출력 문장을 단어 하나씩 생성하여 출력하는 Decoder로 이루어져 있다. 여기서 Encoder와 Decoder는 각각 다른 파라미터를 가지고있는 RNN모델이다.

Encoder의 마지막 time step에서의 hidden state벡터는 Decoder의 h0, 즉 첫번째 time step의 입력으로 주어지는 hidden state로써의 역할을 한다. 그리고 Decoder의 첫번째 time step 입력으로는 start토큰인 <SOS>토큰을 입력하게 되고 time step 출력에서 마지막 출력을 나타내는 <END>토큰이 나오게 된다면 최종적인 출력으로 인식해서 출력을 종료하는 과정을 따르게 된다.
하지만 이러한 구조는 Encoder 마지막 time step의 hidden state에 모든 단어들의 정보를 저장하고 있어 LSTM을 사용했다고 하더라도 훨씬 이전에 나타났던 정보가 변질되거나 소실되는 경우가 생길 수 있다는 단점이 있다. 이를 해결하기 위해 문장 입력 순서를 반대로 넣는 편법이 있기도 했지만 Attention이 등장함으로써 문제가 보완되었다.
Attention
Attention모듈은 Seq2seq의 Decoder가 마지막 hidden state만을 입력받아 예측하는 것과는 다르게 Encoder의 hidden state들을 전체적으로 Decoder에게 제공하고 그 hidden state들 중에 어떤것이 가장 필요한지 적절히 선별하여 예측에 도움을 주는 방식이다. 예를 들어 사람이 글을 읽을 때를 생각해 보면 읽는 도중 반복적으로 이전 내용을 확인하면서 문맥을 파악하는 과정을 거치게 된다. 이러한 개념을 모델에 도입하기 위해 사용한 것이 Attention 모델인 것이다.

이 Attention은 Decoder의 새로운 hidden state를 구하고 이 hidden state와 각각의 Encoder time step의 hidden state를 내적하여 Attention Scores를 구해준다. 그 후 구해진 Attention Scores를 hidden state벡터의 가중치로써 사용하여 가중평균 Attention output 벡터를 구할 수 있다. 마지막으로 최종 output 레이어에서 Decoder time step의 hidden state벡터와 Attention output을 concat하여 출력하여 동작한다.
이러한 Attention방식을 이용하여 모델 학습을 할 때 기존 방식대로 정답을 알려주는 라벨링 방법과 다른 형태가 존재한다. 바로 Teacher forcing(티처포싱)이다. 티처포싱은 디코더의 다음 time step에 입력값으로 이전 time step의 결과값이 아닌 실제 ground truth값을 넣어 학습하는 형태를 말한다. 위의 그림으로 예를 들면 처음 <START>토큰이 입력으로 들어가고 the, poor 등이 순차적으로 입력된다. 그런데 만약 the입력값에 대한 예측값이 poor이 아닌 don’t가 나온다면 그 이후 time step들은 꼬이게 될것이다. 그래서 예측값이 don`t가 나왔어도 정답값인 poor을 입력값으로 넣어주게 되는 방법이다. 이처럼 예측값을 입력값으로 넣어주는 것이 아닌 정답값을 입력값으로 넣어주게되는 것이 티처포싱인 것이다.
이러한 티처포싱방법은 Decoder에서 추론을 할 때 정답이 아닌 값이 입력값으로 들어가지 않아 학습이 빨라지지만 주어진 데이터로 학습할때와 실제 테스트 데이터로 테스트할 때의 결과가 달라질 수 있다는 장단점이 있다.
Attention Mechanism
Attention에는 기본적인 Attention기법 뿐만아니라 다양한 메커니즘이 존재한다.
- Luong - dot : 간단한 내적을 통한 어텐션 측정 기법
- Luong - general : 어텐션을 구하고자 하는 두 벡터 사이에 학습 가능한 파라미터로 구성된 행렬을 곱함
- Luong - concat : 어텐션을 구하고자 하는 두 벡터를 concat하여 선형변환으로 감싸 계산
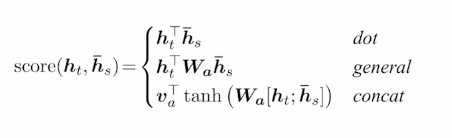
Attention의 장단점
Attention은 Seq2seq의 고질적인 문제를 아주 잘 해결했다. 이를 통해 Machine translation 분야에서 성능 향상을 이끌어냈다. 어떤 time step에 집중해야할지 알려주어 길이가 길어져도 앞에서 학습한 정보를 잊어버리지 않게 만들었기 때문이다. 또한 Seq2seq에서는 마지막 time step에서 모든 정보를 다 담고있는 hidden state를 Decoder에게 전달해 Bottleneck problem(병목현상)이 발생했는데 Attention에서는 한번에 정보를 전달하지 않기 때문에 문제를 해결해주었다. 마지막으로는 Seq2seq의 기반인 RNN모델에서 기울기 폭발/소실(Gradient vanishing/exploding)문제를 Attention구조에서 한번에 가중치를 업데이트 함으로써 해결하였다.
하지만 Attention은 모든 입력값간의 관계를 계산하기 위해 쌍을 이루는 모든 입력값에 대한 가중치를 계산해 계산 복잡성이 증가할 수 있고 추가적인 메모리와 계산 리소스를 필요로해 자원소모가 일어날 수 있는 단점도 존재한다.