Transformer는 2017년 Attention is All You Need라는 구글에서 발표한 논문에서 제안되었다. Transformer는 기존에 Seq2seq과 같이 Encoder-Decoder 구조를 그대로 사용하였으나 RNN을 사용하지 않고 Self-Attention을 사용한 새로운 모델이다.
Long-Term Dependency
RNN과 같은 기존 모델은 입력 길이가 길어질 수록 앞의 정보가 유실되거나 변형되는 Long-Term Dependency문제가 있었다. 예를 들어 I go home이라는 문장이 입력으로 들어온다고 하면 home 단어가 입력되는 time step에서 앞서 입력된 I와 go에 대한 정보도 담겨있게 된다. 하지만 입력 문장이 길어지면 길어질 수록 마지막 time step에서는 더 많은 정보를 가지게 되어 처음 입력된 정보가 변형될 수 있게 된다. 이와 같은 문제를 Long-Term Dependency라고 한다. 이를 해결하기 위해 LSTM, GRU와 같은 해결방안이 나왔지만 이 조차도 Long-Term Dependency 문제를 완벽하게 해결하지 못하는 RNN의 고질적인 문제였다. 그래서 다른 해결책으로 나온 것이 Bi-Directional RNNs와 Transformer이다.
Bi-Directional RNNs
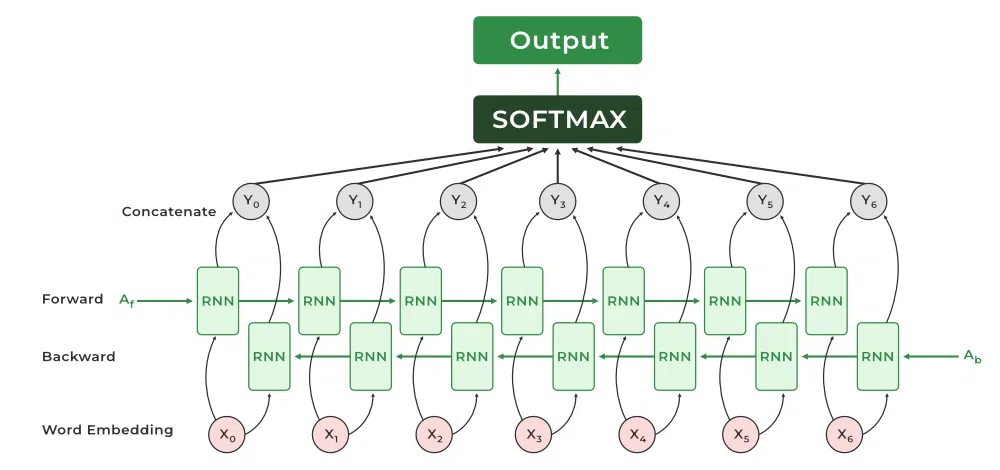
Bi-Directional RNNs는 말 그대로 양 방향의 RNN을 사용한 모델이다. 이 모델은 Forward RNN과 Backward RNN 두 개의 RNN을 만들고 두 RNN에 대한 각각의 hidden state를 가져와서 concat을 해 2배 크기의 차원을 가지는 hidden state를 출력한다. 이렇게 되면 출력된 hidden state는 단일 RNN에 비해 멀리 떨어진 정보도 잘 담고있어 결과에 보다 잘 반영된다. 하지만 이는 완벽한 방법은 아니다.
Transformer
앞서 말한 Transformer구조는 Long-Term Dependency문제를 해결하였다. 이 구조는 모델에 들어가는 입력과 출력은 RNN과 동일하지만 입력에서 주어진 Query(목적이 되는 단어)와 입력 벡터의 Key(입력 전체의 벡터) 사이의 유사도를 계산하여 그 값에 softmax를 취해 value벡터에 곱해 출력값을 계산한다. 그 후 선형결합을 통해 최종 output 벡터를 만들어주는 것이 Transformer이다. 이제부터는 Transformer의 구조에 대해 설명한다.
![]()
Self-Attention
Transformer는 Encoder에서 Multi-head Self-Attention 모듈을 사용한다. 이를 설명하기 전에 Self-Attention부터 천천히 알아보자. Self-Attention은 문장에서 각 단어끼리 얼마나 관계가 있는지를 계산해서 반영하는 방법으로 문장 안에서 단어들 간의 관계를 파악할 수 있는 방법이다. Self-Attention은 이전의 Attention에서 설명한 메커니즘과 거의 유사하다. Attention은 Decoder의 hidden state와 Encoder의 hidden state를 내적하여 Attention Score로 연관성의 정도를 구해 멀리 떨어져있어도 얼마나 연관되어있는지 잘 알 수 있는 방법이었다. Self-Attention은 여기서 더 발전하여 Decoder의 hidden state와 내적하는 것이 아닌 Encoder의 hidden state와 내적하여 유사도를 구하는 방식이다.
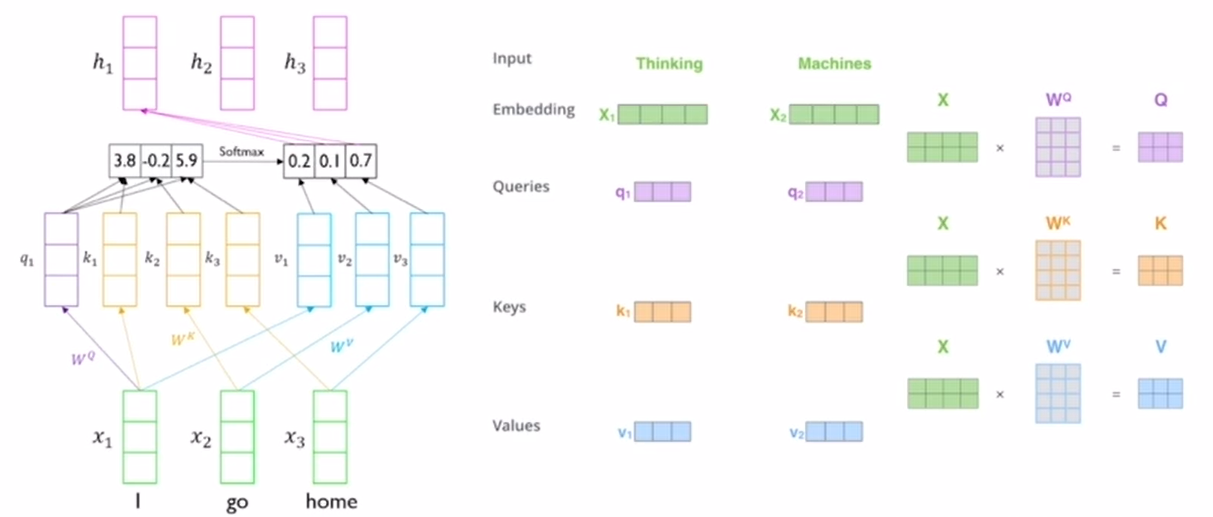
Self-Attention은 Query, Key, Value 벡터를 입력으로 받는다. 주어진 쿼리(Query)에 대해서 모든 키(Key)와의 유사도를 각각 구해 키와 매핑되어 있는 값(Value)에 반영하는 것이 Attention의 메커니즘이기 때문이다. 위의 이미지로 예를 들면 처음에 I에 대한 벡터가 가중치 Wq와 곱해져 Query로 들어가고 Key는 나머지 단어들인 I, go, home 벡터들과 가중치 Wk가 곱해져 들어가 둘의 내적을 구한 뒤 softmax함수를 통과시켜 score를 구한다. 그 후 Value 값에 I, go, home 벡터들과 가중치 Wv를 곱한 값이 들어가 score값과 곱해 선형결합을 거쳐 Attention 벡터를 출력하게 되는것이다.
이처럼 Self-Attention은 내적에 대한 유사도만 높다면 서로 멀리 떨어져 있어도 알맞는 정보를 가져올 수 있어 거리와 상관없이 잘 작동하게 된다.
Sclaed Dot-Product Attention
Scaled Dot-Product Attention의 구조는 아래와 같다. 이는 Self-Attention과 매우 유사하다.
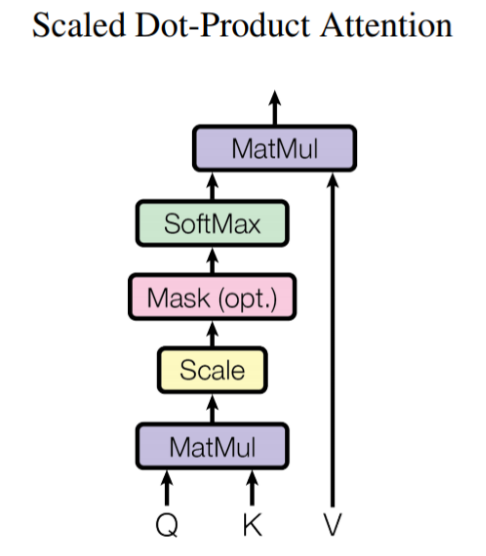
Self-Attention과 유사하게 Attention 스코어를 구해 유사도를 구하는 것은 같지만 내적 연산 후에 스케일링을 한다는 점이 다르다. Scaled Dot-Product Attention에서는 아래의 수식처럼 Query와 Key를 내적한 값에 dk에 루트를 씌운 값으로 scaling해준 후 softmax를 적용한다.
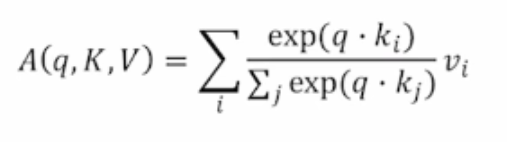
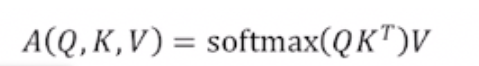
생성된 Attention 벡터의 평균과 분산이 제각각이고 차원이 너무 커지게 된다면 분산도 같이 커지게 되어 학습이 잘 이루어지지 않을 수 있다. 따라서 벡터의 평균을 각 row에서 빼주고 차원의 크기인 dk에 루트를 씌워 나누어 준다. 이렇게 되면 벡터의 평균이 0이 되고 분산이 1이 되어 학습이 잘 이루어질 수 있다.