Transformer(1)에서는 Transformer의 Self-Attention과 Scaled Dot-Product Attention에 대해 설명했다. 이번에는 Multi-Head Attention과 Attention외의 모듈들인 Block-Based Model, Positional Encoding, Learning Rate Scheduler에 대해 설명할 것이다.
Multi-Head Attention
Transformer에서 사용되는 Multi-Head Attention을 간단히 설명하자면 Self-Attention을 동시에 병렬적으로 여러번 진행하는 것이다.
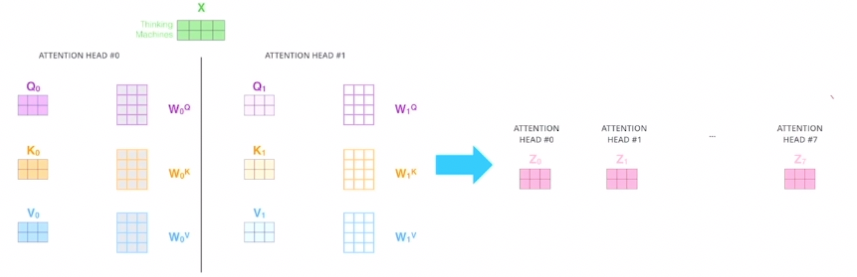
위 이미지와 같이 선형변환 후 각 query 벡터에 대한 인코딩된 벡터 Z를 하나만 구하는 것이 Self-Attention인데 이를 여러개로 늘려서 Z7까지 구하는 것을 볼 수 있다. 이렇게 각각의 어텐션들이 수행되는 것을 헤드라고 하여 Multi-head Attention이라고 부르는 것이다. 이 모듈의 계산 과정으로는 먼저 각 헤드별로 존재하는 선형변환 벡터를 이용해 각각의 어텐션 벡터 결과값을 얻어서 이를 전부 concat하여 최종 결과값을 얻는다. 예를 들어 위 이미지처럼 head가 8개 일때 각 어텐션 결과 벡터가 차원이 3인 벡터라고 하면 총 8개의 헤드로부터 나온 어텐션 벡터들을 concat하여 최종 24차원의 최종 벡터를 얻게 되는 것이다.
이렇게 헤드를 병렬적으로 여러번 진행하는 이유는 바로 특정한 단어에 대해 서로 다른 기준으로 여러 측면의 정보를 가져와야 할 필요가 있기 때문이다. 예를 들어 여러 문장이지만 하나의 sequence로 볼 수 있는
- I went to the school. I studied hard. I came back home and I took the rest.
라는 문장이 있을 때 I 라는 주체가 하는 행동을 중심으로 하는 정보들인 went, studied, came back, took을 가져올 수 있게 되고 또 다른 측면에서는 I 라는 주체가 학교에서 집으로 이동한 장소에 대한 정보를 가져올 수 있다. 이러한 방식으로 서로 다른 다양한 측면에 대한 정보를 병렬적으로 뽑고 이를 다 합치게 되는 형태로 Multi-Head Attention이 이루어 지게 되는것이다.
Block-Based Model
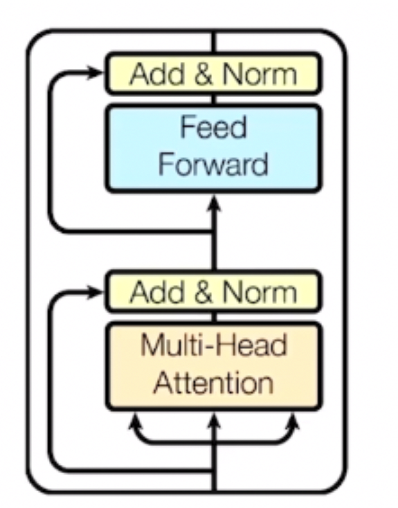
Block-Based Model은 여러개의 층이 모여 하나의 모듈을 구성한 것이다. 위 이미지는 멀티헤드 어텐션의 입력으로 Query, Key, Value 3개의 벡터가 들어가게 되고 그 결과값으로 Residual Connection과 layer normalization을 한 뒤 feed forward와 residual connection, layer normalization을 하게된다.
여기서 residual connection이란 입력으로 들어가는 단어의 임베딩 벡터와 멀티 헤드 어텐션을 거쳐서 나온 임베딩 벡터를 서로 더해주는 방식이다. 이때, 벡터를 서로 더해야하므로 입력으로 들어가는 임베딩 벡터의 차원과 멀티헤드 어텐션을 거쳐서 나온 임베딩 벡터의 차원은 동일해야한다. 이렇게 진행하는 이유는 gradient vanishing문제도 해결하고 학습도 보다 안정화 시킬 수 있기 때문에 사용하는 것이다.
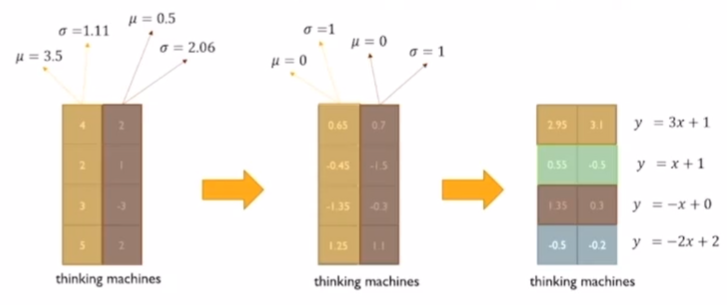
또한 layer normalization은 평균과 분산을 원하는 대로 주입할 수 있게 만드는 방식이다. 먼저 normalization으로 평균을 0, 분산을 1로 만들어 주고 Affine Transformation을 통해서 y=ax+b를 적용해주면 원하는 평균과 분산을 주입할 수 있게 된다.
Positional Encoding
RNN에서는 위치 정보를 따로 알려주지 않아도 알 수 있었지만 Transformer에서는 위치 정보를 알 수 없다. 따라서 단어에 대한 각 위치를 나타내는 정보를 추가하기 위해 Positional Encoding방식을 사용하였다.
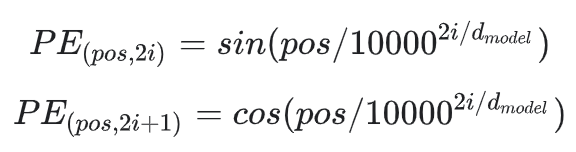
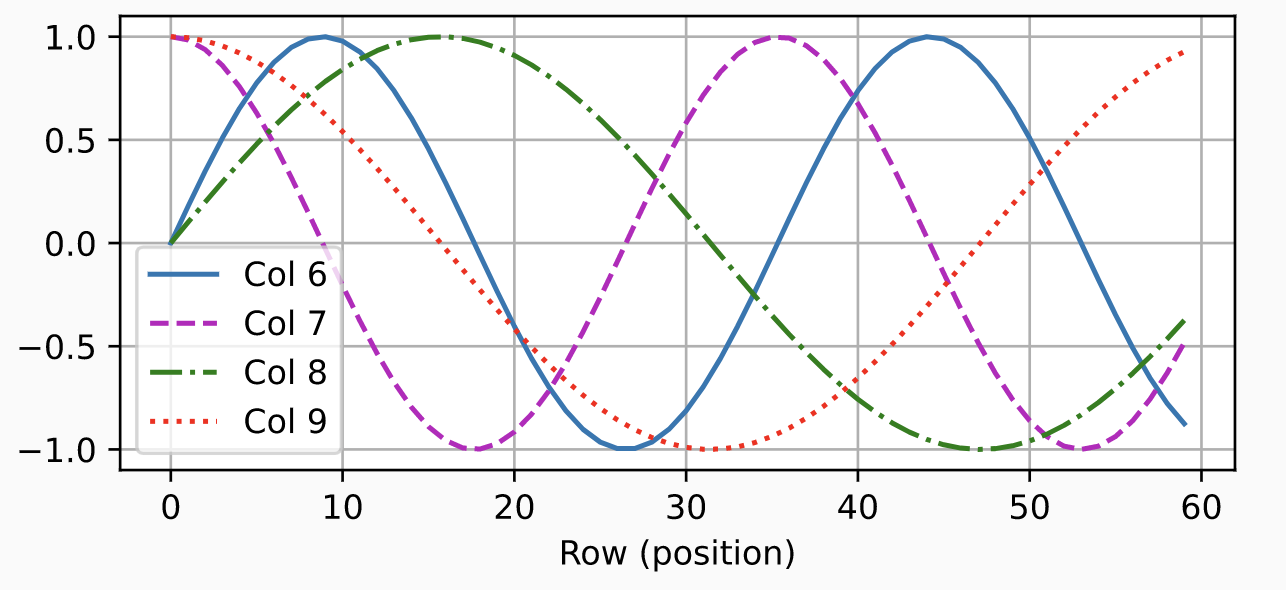
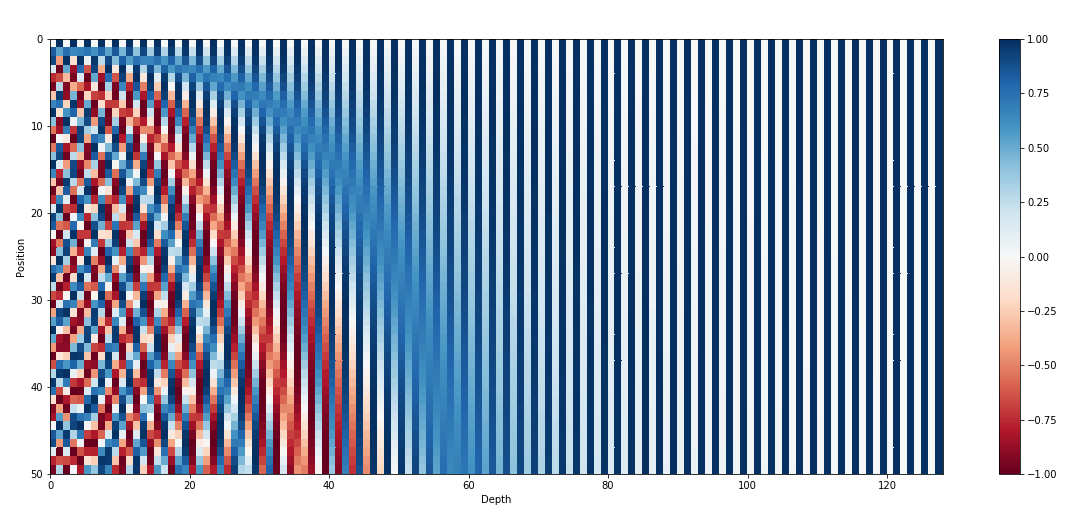
Positional Encoding은 입력된 순서를 구분할 수 있게 해주는 겹치지 않는 상수 벡터를 더해주는 방식이다. 주기함수인 sin과 cos을 통해 각 벡터들이 주기를 가지게 되는 포지션 정보를 갖게 되는 것이다.
Learning Rate Scheduler
Learning Rate Schdeuler는 learning rate 파라미터를 고정시키는 것이 아니라 학습 도중에 적절히 바꿔가면서 사용할 수 있게 만드는 방식이다.
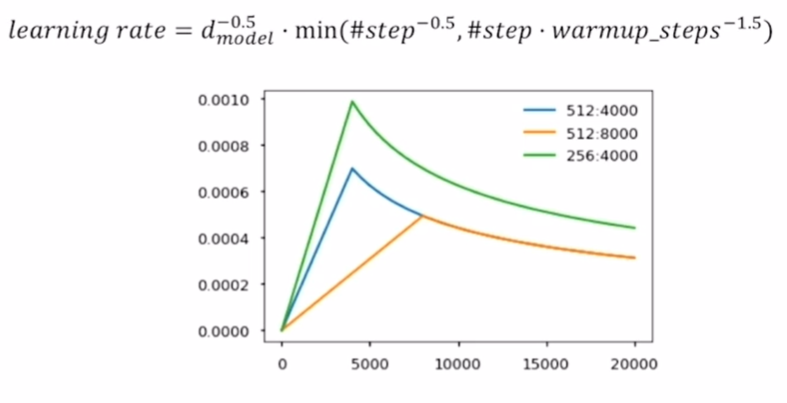
역전파를 진행하면서 기울기가 변하게 되는데 처음에는 기울기가 클수밖에 없다. 그래서 learning rate를 크게 해서 기울기를 빠르게 줄여주고 최적의 값에 다가갔을때는 learning rate를 작게 줄여 안정적으로 만들 수 있다.