사람이 사용하는 언어의 문장에는 여러 단어가 존재하고 각 단어에는 여러가지 의미가 있을 수 있으며 비슷한 의미를 가진 단어와 정반대의 의미를 가진 단어들과 같이 언어에는 여러 복잡한 의미가 얽혀있다. 그렇다면 이러한 단어를 컴퓨터가 쉽게 인식하고 처리하게 하려면 어떻게 전달해야할까?
간단하게 생각하면 단어를 벡터화 시키면 된다. 단어의 벡터화를 시키는 가장 간단한 방법은 One-hot encoding이다. One-hot encoding은 N개의 단어를 N차원의 벡터로 표현하는 것이다. 예를 들어 ‘강아지’, ‘어렵다’, ‘개’ 라는 단어가 있다고 하면 이를 벡터화 시켜 ‘강아지’ = [1 0 0], ‘어렵다’ = [0 1 0], ‘개’=[0 0 1]과 같이 나타낼 수 있는 것이다.
하지만 이 방식은 단점이 존재한다. One-hot vector로 표현하게 되면 하나의 요소만 1, 나머지는 0이 되어 벡터의 차원이 커질수록 공간적 낭비가 심해지게 된다. 또 하나의 단점은 벡터 표현에 단어와 단어 간의 관계가 전혀 드러나지 않는다는 것이다. ‘강아지’와 ‘개’라는 단어에서 의미가 비슷함에도 불구하고 전혀 다른 벡터로 표현된다. ‘강아지’와 ‘개’ 사이의 관계가 ‘강아지’와 ‘어렵다’ 사이의 관계와 차이가 없게 되어버린다. 그래서 이와 같은 방식으로는 컴퓨터가 쉽게 인식하기 어렵다. 따라서 이를 해결하기 위해 Word Embedding을 사용하게 된다.
Word Embedding
Word Embedding이란 자연어 처리에서 가장 기본이 되는 방법으로 각 단어를 좌표공간에 최적의 벡터로 표현하는 기법을 말한다. 이는 One-hot vector처럼 벡터를 단어집합의 크기로 설정하는 것이 아니라 사용자가 설정한 값으로 customize하여 0 과 1 사이의 binary한 값에서 벡터 표현의 차원을 조정할 수 있다. 벡터에 단어의 의미를 담을 수 있게 되는 것이다. ‘왕’과 ‘여왕’의 관계와 ‘남자’와 ‘여자’의 관계가 비슷하다는 것 처럼 Word Embedding은 비슷한 의미의 단어들은 비슷한 벡터로 표현할 수 있다.

이러한 Word Embedding을 사용하는 대표적인 방법으로 Word2Vec, Glove가 있다.
Word2Vec
Word2Vec은 Word Embedding을 만드는 방법론 중 하나로 문장 내에서 비슷한 위치에 등장하는 단어는 비슷한 의미를 가진다는 것을 뜻한다. 즉, 증심 단어 주변에 등장하는 단어들을 퉁해 중심 단어의 의미를 표현하는 방법이다.
예를 들어 위와 같은 문장에서 빈칸에 들어갈 말로 여러가지를 예측할 수 있다. italian, mexican, korean 등등 여러 단어가 들어갈 수 있지만 chair, desk같은 맥락과 맞지 않은 단어는 적절하지 않다. 이처럼 특정 단어 주변의 단어들을 보면 그 단어를 알 수 있기 때문에 Word2Vec는 주변 단어를 통해 중심 단어를 유추 하게 된다.
CBOW, Skip-Gram
앞에서 설명한 Word2Vec안에도 CBOW와 Skip-gram 두가지 방식이 존재한다.

간단히 설명하면 그림과 같이 CBOW는 하나의 맥락으로 단어를 예측하는 방식이고 Skip-gram은 반대로 하나의 단어로 맥락을 예측하는 방식이다.

각 방식은 데이터셋을 만들 때 window size를 지정하여 sliding window라는 방법을 사용한다. window size는 중심단어 기준으로 앞과 뒤에서 몇개의 단어까지 볼지 정해주는 값이고 sliding window는 window 안의 단어를 다 보고 window를 밀어서 중심단어를 계속 바꾸는 방식이다.
하지만 이러한 Word2Vec에는 vocabulary가 커질 수록 계산 비용이 커진다는 단점이 있다. 이를 해결하기 위해서는 softmax를 통해 확률을 구하고자 할 때 분모로 모두 더하는 방식인 Hierarchical softmax와 전체 단어 집합에서 문맥 단어가 아닌 k개의 단어를 임의로 추출하는 방법인 Negative Sampling을 사용할 수 있다.
Glove
Glove는 카운트 기반과 예측 기반을 모두 사용하는 방법론으로 예측 기반의 방법론으로 코퍼스 내의 전체적인 통계 정보인 동시 등장 횟수(Co occurrence) 를 활용하는 모델이다. 위 방법은 동시 등장 횟수를 사전에 미리 계산하여 동시 등장 행렬에 저장해 놓는다. 단어의 동시 등장 행렬은 행과 열을 전체 단어 집합의 단어들로 구성하고, i 단어의 윈도우 크기(Window Size) 내에서 k 단어가 등장한 횟수를 i행 k열에 기재한 행렬이다.
예를 들어 위 텍스트 데이터가 있다고 가정하자.
- I like deep Learning
- I like NLP
- I enjoy flying
윈도우 크기가 1일 때 위의 텍스트를 가지고 구성한 동시 등장 행렬은 이와 같다.
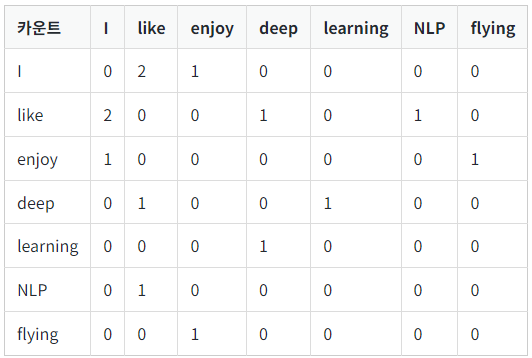
따라서 이 정보를 이용해 동시 출현 빈도가 높은 단어 쌍에 낮은 가중치를 부여하고 동시 출현 빈도가 낮은 단어쌍에 높은 가중치를 부여하여 예측하게 된다.